Abstract
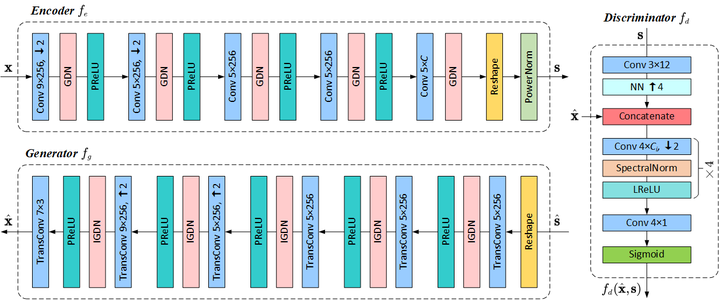
As one novel approach to realize end-to-end wireless image semantic transmission, deep learning-based joint source-channel coding (deep JSCC) method is emerging in both deep learning and communication communities. However, current deep JSCC image transmission systems are typically optimized for traditional distortion metrics such as peak signal-to-noise ratio (PSNR) or multi-scale structural similarity (MS-SSIM). But for low transmission rates, due to the imperfect wireless channel, these distortion metrics lose significance as they favor pixel-wise preservation. To account for human visual perception in semantic communications, it is of great importance to develop new deep JSCC systems optimized beyond traditional PSNR and MS-SSIM metrics. In this paper, we introduce adversarial losses to optimize deep JSCC, which tends to preserve global semantic information and local texture. Our new deep JSCC architecture combines encoder, wireless channel, decoder/generator, and discriminator, which are jointly learned under both perceptual and adversarial losses. Our method yields human visually much more pleasing results than state-of-the-art engineered image coded transmission systems and traditional deep JSCC systems. A user study confirms that achieving the perceptually similar end-to-end image transmission quality, the proposed method can save about 50% wireless channel bandwidth cost.
Sixian Wang
Ph.D Student
My research focuse on semantic communications, source and channel cod- ing, and computer vision.