Abstract
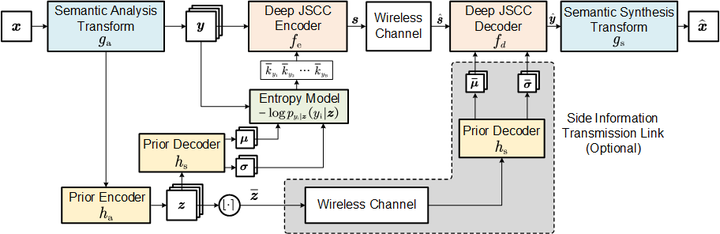
In this paper, we propose a new class of high-efficiency semantic coded transmission methods for end-to-end speech transmission over wireless channels. We name the whole system as deep speech semantic transmission (DSST). Specifically, we introduce a nonlinear transform to map the speech source to semantic latent space and feed semantic features into source-channel encoder to generate the channel-input sequence. Guided by the variational modeling idea, we build an entropy model on the latent space to estimate the importance diversity among semantic feature embeddings. Accordingly, these semantic features of different importance can be allocated with different coding rates reasonably, which maximizes the system coding gain. Furthermore, we introduce a channel signal-to-noise ratio (SNR) adaptation mechanism such that a single model can be applied over various channel states. The end-to-end optimization of our model leads to a flexible rate-distortion (RD) trade-off, supporting versatile wireless speech semantic transmission. Experimental results verify that our DSST system clearly outperforms current engineered speech transmission systems on both objective and subjective metrics. Compared with existing neural speech semantic transmission methods, our model saves up to 75% of channel bandwidth costs when achieving the same quality. An intuitive comparison of audio demos can be found at this https URL.
Shengshi Yao
Ph.D Student
My research focuse on semantic communications, source and channel cod- ing, and computer vision.
Jincheng Dai
Supervisor
Sixian Wang
Ph.D Student
My research focuse on semantic communications, source and channel cod- ing, and computer vision.