Abstract
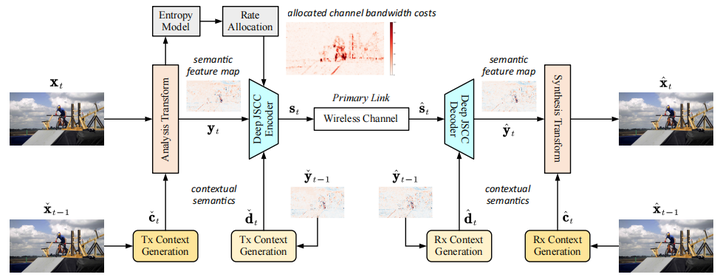
In this paper, we design a new class of high-efficiency deep joint source-channel coding methods to achieve end-to-end video transmission over wireless channels. The proposed methods exploit nonlinear transform and conditional coding architecture to adaptively extract semantic features across video frames, and transmit semantic feature domain representations over wireless channels via deep joint source-channel coding. Our framework is collected under the name deep video semantic transmission (DVST). In particular, benefiting from the strong temporal prior provided by the feature domain context, the learned nonlinear transform function becomes temporally adaptive, resulting in a richer and more accurate entropy model guiding the transmission of current frame. Accordingly, a novel rate adaptive transmission mechanism is developed to customize deep joint source-channel coding for video sources. It learns to allocate the limited channel bandwidth within and among video frames to maximize the overall transmission performance. The whole DVST design is formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion performance under perceptual quality metrics or machine vision task performance metrics. Across standard video source test sequences and various communication scenarios, experiments show that our DVST can generally surpass traditional wireless video coded transmission schemes. The proposed DVST framework can well support future semantic communications due to its video content-aware and machine vision task integration abilities.
Sixian Wang
Ph.D Student
My research focuse on semantic communications, source and channel cod- ing, and computer vision.